the wayback machine the trove
The Wayback Machine is one way to recover this information. The Internet Archive opens its doors and drives towards a goal of Universal Access to Knowledge and encourages contributions and uploads from our audience on a global scaleIn some cases like our Netlabels section the contributors are often the creators as well publishing open-licensed music at the Archive.

6 Of Our Favorite Digital Time Capsules
A book club where the wanderers travellers and adventurers who peruse the shelves of The Trove gather to discuss its large range of content.

. As a shop thats been continuously operating for forty-five years in one location weve got some dusty piles of old parts in the basement. Its founders Brewster Kahle and Bruce Gilliat developed the Wayback Machine to provide universal access. An illustration of two cells of a film strip.
Researching archived websites also delivers a treasure trove of historical information. An illustration of a 35 floppy disk. Its perfect for uncovering historical data.
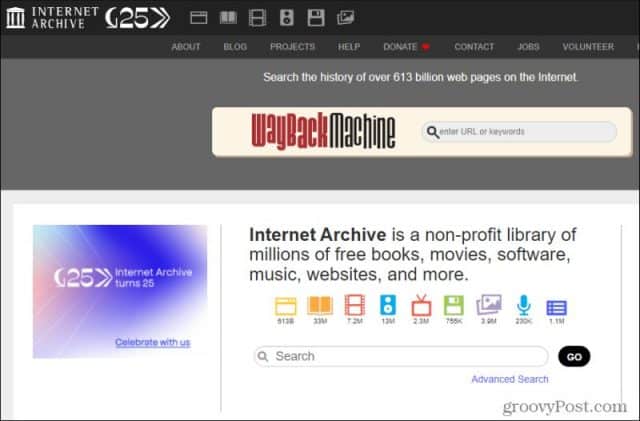
Explore more than 639 billion web pages saved over time. At the time the World Wide Web was only 25 terabytes in size. As a prolific independent creator Kortthalis Publishing I ask that if someone is going to download my PDFs from the trove they at least do me the courtesy of posting feedback writing a review blogging a session report where my material was used or sending out a few DriveThru links around social media.
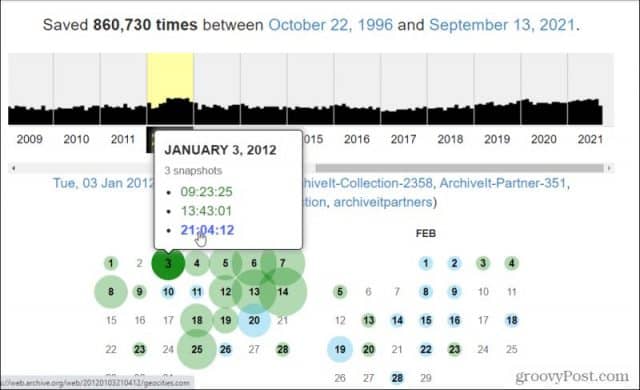
Others however are doing their part to make sure near. You can even find a trove of historical robotstxt files archived. Created in 1996 and launched to the public in 2001 it allows the user to go back in time and see how websites looked in the past.
Use the Australian Web Archive to navigate Australian websites at different points in time and view historical web pages. The trove dates back to late 1996 and comprises at least fourteen petabytes a figure we base on a 2012 declaration the archive hit 10 petabytes and a later post explaining that a fund-raising drive for another four petabytes had succeeded. An illustration of an open book.
An illustration of two photographs. In October of 1996 engineers at the the San Francisco-based Internet Archive launched their first web crawlers taking snapshots of web pages. An illustration of an audio speaker.
The Internet Archives Wayback Machine has announced that it has indexed four hundred billion web pages. When searching the Websites category in Trove results are displayed as a list of domains rather than webpages. The wayback machine.
There are a ton of other SEO uses for Wayback Machine you may find useful. Posted on February 4th 2019 by Broadway Bicycle School. You can even find a trove of historical robotstxt files archived.
The trove dates back to late 1996 and comprises at least fourteen petabytes a figure we base on a 2012 declaration the archive hit 10 petabytes and a later post explaining that a fund-raising drive for another four. Keeping the Wayback Machine updated with current data is just one way in which the organization seeks to. This treasure trove of content is stored in high-capacity hard drives at the Internet.
An illustration of a computer application window Wayback Machine. There are a ton of other SEO uses for Wayback Machine you may find useful. The Internet Archives Wayback Machine has announced that it has indexed four hundred billion web pages.
First off totally agree that guy is a douche but for other reasons. The Internet Archives Wayback Machine is a treasure trove containing 439 billion web pages saved over 19 years of internet history. Gotta be honest I personally use the Wayback Machine 23 times a week.
The Wayback Machine is an initiative of the Internet Archive a 501c3 non-profit building a digital library of Internet sites and other cultural artifacts in digital form. The Wayback Machine is a digital archive of the World Wide Web founded by the Internet Archive a nonprofit based in San Francisco California. 2925 likes 9 talking about this.
Its perfect for uncovering historical data. Select a link to enter the Australian Web Archive. A trip in the wayback machine In my continuing efforts to scan and digitize old photos I recently pulled one of the binders out of the closet and found a trove of medium format transparencies dating back to my early years at USA TODAY.
While we have a self-serve used section in the back corner of the shop that can be a treasure trove I wanted to share some of the fun new old. Company websites a rich resource for competitive data product sheets or analysis change over time. But much isnt available on both.
Wayback machine Internet Archive web archiving Brewster Kahle Bruce Gilliat. Ive created a composite based on combining a full retrieval of everything wayback has for both domains plus my own partial crawl but even with all three sources combined its nowhere near complete.

Internet Archive Tv News Search Captions Borrow Broadcasts

Internet Archive Tv News Search Captions Borrow Broadcasts

Top 9 Wayback Machine Alternative Sites Web Archive Sites

Internet Archive Wayback Machine Wayback Machine Internet Archive Financial Markets

Underdark Jungle Cavern River Bridge Fantasy Map Dungeon Maps Adventure Map

10 Best Deep Search Engines To Explore The Invisible Web
10 Best Deep Search Engines To Explore The Invisible Web

Emulation Archives Internet Archive Blogs

Event Archives Internet Archive Blogs

Mr Peabody Wayback Machine Famous Cartoons Old School Cartoons Favorite Cartoon Character

Image Archive Archives Internet Archive Blogs

Three Ways To Celebrate Public Domain Day In 2022 Internet Archive Blogs
Event Archives Internet Archive Blogs

Image Archive Archives Internet Archive Blogs
10 Best Deep Search Engines To Explore The Invisible Web

Three Ways To Celebrate Public Domain Day In 2022 Internet Archive Blogs

What Is The Internet Archive And Why Is Everyone Not Talking About It Moments

0v1ul0mrjbtg1m

10 Ways To Explore The Internet Archive For Free Internet Archive Blogs Internet Archive Interesting Reads Archive